Multimodal artificial intelligence is gaining popularity as technologies like mobile phones, vehicles, and wearables use different modalities to create seamless and robust user experiences.
The term “multimodal” refers to the different ways in which humans communicate with systems. Depending on the user's preference or abilities, these could be interaction modalities like touch, speech, vision, gestures, haptics, etc.
These modalities might have different ways they are expressed or perceived. For example:
Language Modality
Expression: Users can interact through natural languages, enabling them to type or speak commands conversationally.
Perception: The system processes and understands the input through speech recognition or text analysis, providing relevant responses or actions based on the interpreted language.
Vision Modality
Expression: Users interact through a camera or other vision-capturing devices, either by taking pictures, recording videos, or providing a live video feed.
Perception: Computer vision algorithms analyze the visual data, identifying objects, patterns, or gestures. This information is then used to trigger specific actions or provide relevant feedback based on the visual input.
Each response for both modalities can be language-to-vision or vision-to-speech, among others. Multimodal AI is significant because it accommodates diverse preferences and communication abilities, making technologies like smart devices more inclusive and adaptable for everyday tasks from voice commands and touch interactions to visual recognition.
Why Multimodal AI?
Conventional supervised or unsupervised learning algorithms have been used with specific data types like images, text, or speech that have made training straightforward. But in reality, data comes with different modalities (e.g., vision combined with sound and text captions in movies), each conveying unique information to enhance its overall understanding.
A classic example illustrating the need for multimodal understanding is the McGurk effect. This phenomenon shows that our perception of speech sounds can be influenced by visual cues, underlining the complex interplay between different senses and modalities.
The primary motivation behind multimodal AI is to create models capable of capturing the nuances and correlations between the different data types, thereby representing information more comprehensively.
Examples of multimodal systems include GPT-4V, Google’s Gemini, and Microsoft’s open-source LLaVA, which combine text and image modalities, demonstrating the power of integrated data processing. Despite the potential, multimodal models face challenges such as accurate representation, alignment, and reasoning across modalities, which are ongoing areas of research and development in the field.
Types of modalities
There are three main types of modalities in multimodal machine learning, and they include:
Unimodal (Homogenous Modalities):
These modalities involve one data type with a similar structure (e.g., text-only or image-only).
An example of unimodal (homogeneous) modalities:
Imagine a facial recognition system designed to identify individuals. This system is fed with two types of data sources:
Surveillance camera footage: Video streams from various surveillance cameras installed in different locations. Each camera might have varying resolutions, angles, or lighting conditions.
Uploaded photographs: Images uploaded by users or authorities, such as passport photos or snapshots from personal devices. These images will have different qualities, backgrounds, and formats.
In this scenario, although both data sources are essentially images (hence homogeneous in terms of modality), they differ in their origin, quality, and context.
Multimodal (Heterogenous) Modalities
These involve multiple data types (e.g., text, image, and audio). The challenge in multimodal systems is integrating and analyzing these diverse data types, which may vary significantly in structure and format. This can be text-image and speech-video modalities, among a variety of others. Models with heterogeneous modalities are complex, and the model finds the relationships between the different data types.

Fig. 1. The dimensions of heterogeneity. Source: Multimodal Machine Learning | CVPR Tutorial
An example of multimodality (heterogenous modality)
Imagine a virtual classroom environment where AI gauges student engagement and emotional responses during a lesson. This system uses two different modalities:
Audio (speech) analysis: The system analyzes the students' vocal tones, pitch, and speech patterns. For instance, variations in tone or pitch might indicate excitement, confusion, or boredom.
Video (facial expression) analysis: Simultaneously, the system evaluates the students' facial expressions using video input. It looks for visual cues such as smiles, frowns, or furrowed brows, which can signify happiness, confusion, or frustration.
The AI system integrates these two data streams to better understand the students' emotional states. For example, a student might verbally express understanding (e.g., saying "I get it"), but their facial expression could show confusion or doubt. By analyzing speech and facial expressions, the AI can more accurately assess the student's true emotional response, leading to insights such as whether the student might need additional help or clarification on the topic.
In this scenario, the multimodal AI system uses heterogeneous modalities (audio and video) to capture a fuller picture of the student's engagement and emotional states, which can be crucial for adaptive learning and personalized education.
Interconnected (Complementary) Modalities
This concept refers to inherently correlated (or linked) modalities, where information from one enhances the understanding of another. This interconnectedness allows for a more comprehensive understanding of the overall context.
An example of interconnected (complementary) modalities
Imagine a car navigation system that uses voice commands (audio modality) and visual map displays (visual modality) to assist drivers. Here's how these interconnected modalities work together:
Voice command input: The driver uses voice commands to interact with the system, saying things like "Find the nearest gas station" or "Navigate to 123 Main Street." The system processes these audio inputs to understand the driver's requests.
Visual map display: In response to the voice commands, the system updates the visual map display to show the route to the desired destination or the locations of nearby gas stations.
Improved understanding through interconnection: The voice commands provide context and specific requests, which the system uses to generate relevant visual information on the map. Conversely, the visual map display can prompt the driver to provide further voice commands, such as asking for alternate routes or zooming in on a specific map area.
In this example, the interconnectedness of audio and visual modalities creates a more user-friendly and efficient navigation experience. The voice commands allow for hands-free interaction, enhancing driving safety, and the visual maps provide clear and precise navigational information. The system effectively combines these modalities to enhance overall functionality and the user experience.
Cross-modal interactions
Cross-modal interactions cover a broader spectrum of how different modalities can relate to and interact within a multimodal system. Two interactions happen:
Overlapping information: Multiple modalities interact to convey similar or overlapping information. This redundancy can either reinforce the output (for robustness) or add little value. For example, audio signals and lip movements (video) may provide overlapping information about spoken words in speech recognition.
Complementary information: Each modality contributes unique information, improving the overall output. For instance, in an autonomous vehicle, camera feeds (visual data) and LiDAR sensors (spatial data) provide complementary information for navigation and obstacle detection.
These interactions operate across various dimensions:
Modulation types in signal processing: Different modulation methods (additive, multiplicative, and non-additive) affect how signals from various modalities are combined. For example, additive modulation might involve layering audio signals on top of visual data in a video.
Modalities based on components: Systems can be 'bimodal' (e.g., audio-visual), 'trimodal' (e.g., audio-visual-tactile), or involve even more modalities ('high-modal'), each adding a layer of complexity and richness.
Relationships within the system: Entities within a multimodal system may relate through equivalence (similar information), correspondence (related but distinct information), or dependency (one modality influencing another).
Interaction types between elements: These include dominance (one modality overriding others), entailment (one modality leading to conclusions in another), and divergence (modalities providing contrasting information).
Mechanisms in information processing: Processes like modulation (altering signals), attention (focusing on specific modalities), and transfer (moving information between modalities) are crucial for effective data integration and processing of multiple modalities.
Cause-and-effect relationships: Understanding causality and directionality helps determine how one modality might influence or be influenced by another, which is vital for interactive AI systems.
Overall, these interactions and dimensions are pivotal in determining how various modalities within a multimodal system collaborate, influencing the richness of representation and the efficacy of the combined output.
Multimodal AI Training Process
Multimodal machine learning integrates diverse data sources to model relationships between modalities. With varied qualities and structures, these systems create intelligent models that make sense of the world to offer coherent contextual information.
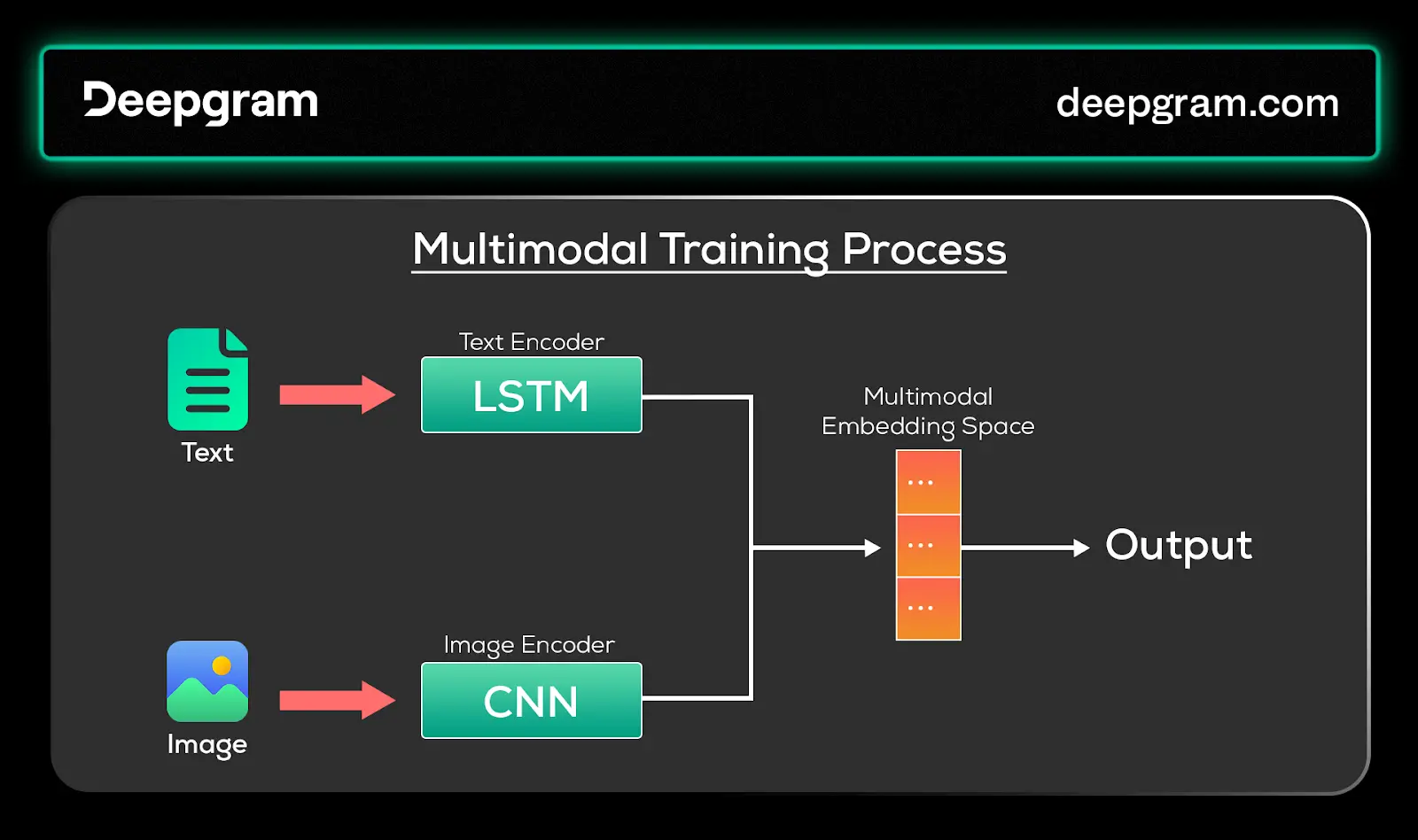
Fig. 2. A high-level view of the training process for multimodal models
A typical multimodal system includes:
Encoders for each data modality: Utilize specialized encoders (like CNNs for images, RNNs or LSTMs for text) to create embeddings that capture the essential characteristics of each data type, ensuring meaningful representation of diverse inputs.
Mechanisms to align embeddings: Techniques like canonical correlation analysis (CCA) or transformers align embeddings from various modalities into a shared space, promoting cross-modal interactions and cohesive understanding within the representation.
Joint representation: Merges aligned embeddings into a unified representation, empowering the system to use information from different modalities for tasks like classification, generation, or decision-making.
Training pipeline: Ideally, a training pipeline is set up to refine encoders and alignment mechanisms through iterative learning. This enhances the system's ability to generate cohesive representations and improves overall performance in handling complex multimodal scenarios.
Where possible, it's beneficial to use pre-trained and reusable components for efficiency.
To continually improve the model, you could use Reinforcement Learning with Human Feedback (RLHF) as a post-training technique or Retrieval-Augmented Generation (RAG).
RLHF ensures the following in multimodal training:
It introduces a human feedback loop to reinforce the training process, providing a richer learning signal and enhancing model generalization with human intuition and expertise. It is especially valuable for complex, multimodal tasks.
Human feedback addresses ambiguities in multimodal scenarios, where context and intent may be nuanced and challenging for traditional models.
The human feedback loop accelerates the learning process, reducing reliance on extensive labeled data and expediting convergence during training.
LLaVA is an excellent example of a large multimodal model (LMM) that utilizes RLHF.
Challenges
According to the survey paper created by Paul Liang et. al., six (6) core challenges in multimodal machine learning are important to consider when training your algorithms:
Representation
In every multimodal interaction, the goal is to create an output that accurately represents the interacting modalities. Challenges arise when the model does not learn the representations of each modality well enough to adequately reflect cross-modal interactions. Depending on your task, you could think of:
How to effectively fuse different modalities into one to improve overall understanding while ensuring they work well together in the output.
How to ensure that each modality aligns seamlessly for accurate associations and correlations to avoid inconsistencies in the representation.
Dealing with situations where one modality contains various or complicated information and how it will be represented.
For example, in a multimodal system analyzing text and images, the representation challenge involves creating a unified structure that accurately combines linguistic patterns and visual features for comprehensive understanding. Mechanisms in information processing like attention or transfer learning, among others.
Alignment
Alignment involves carefully ensuring that information across different modalities harmonizes, promoting accurate associations. This involves recognizing connections between different modalities and constructing an integration built from the underlying data structure to create coherent combinations of all modalities.
A significant challenge is temporal (time) alignment in dynamic modalities, essential for synchronizing data streams like video and audio.
Consider a system aligning spoken words with corresponding textual transcripts. Accurate alignment is important for correctly associating spoken phrases with their corresponding text.
Reasoning
This involves developing robust models that effectively utilize information from multiple modalities to produce an output, considering the problem structure and alignment.
The challenge lies in creating models that leverage multiple modalities through multi-step inferential reasoning, especially in scenarios with conflicting or ambiguous inputs from the modalities.
For example, autonomous vehicles integrate information from sensors (visual and LiDAR data) and textual maps. They reason about the environment, aligning visual input with map data to make informed decisions for safe navigation. It infers that visual cues indicating an obstacle correspond to mapped structures, influencing the vehicle's path for effective manoeuvring.
Generation
This refers to synthesising coherent and contextually relevant output across various modalities, ensuring the meaningful creation of information.
Here, the challenges for the model to consider can be the following, depending on the choice of task:
How to generate concisely summarized representations without losing critical details between modalities.
How to produce coherent and contextually relevant content in the target modality.
How to generate new content that aligns with user preferences or specified criteria.
For a language translation system handling text and images, the generation challenge involves creating translated text that accurately corresponds to the visual context captured in the images.
Transference
This involves addressing issues related to transferring knowledge and models across diverse modalities in multimodal machine learning, ensuring adaptability and consistency.
The challenge is to devise mechanisms that facilitate smooth knowledge transfer while maintaining performance consistency when applying models to domains where data distributions vary significantly.
In a speech recognition system, transference challenges may arise when adapting the model trained in one language to accurately recognize and interpret speech in another.
Quantification
Quantitatively assessing information integration quality, relevance, and effectiveness across multiple modalities is important. The challenge is to define metrics and criteria for objective evaluation, providing a basis for improving the quality of multimodal information processing.
In a sentiment analysis system analyzing text and audio, quantification challenges include developing metrics that accurately measure the alignment between textual sentiment and corresponding emotional cues in the spoken words.
Conclusion
Understanding the relationships between modalities is an exciting and significant part of AI research. This will help researchers and the industry create better and more inclusive products, enabling more intuitive and complete interactions between humans and machines. The more we understand these modalities and their relationships, the closer they reach human-like multimodal communication.
The motivations are wide-ranging—supporting disabled populations by accommodating accessibility needs, facilitating explainability by surfacing connections hidden within single channels, and even further reducing barriers to human-computer cooperation by supporting flexibility and adaptability in communication.